SQL Skills for App Devs
Learn SQL from scratch with a focus on what app devs need to know, from schema design to writing transactions that perform at scale.
Start LearningWhen building a table in a SQL database, one of the most important decisions is what to use for a primary key. This can have a big impact on the efficiency of your queries. It also becomes critically important when you start creating relationships between tables.
Primary keys have certain criteria that must be met. These include:
- Must be unique.
- Must not be null.
In addition, there are some best practices that are often recommended for creating your primary key, including:
- Should be immutable.
- Should be small, fixed-size data types.
- Should be used for common queries.
However, CockroachDB supports online primary key changes and cascading actions. As a result, immutability is less critical. The size of the data types is also less important because the database is scalable, so we aren’t stuck with a fixed amount of disk or memory.
So while these best practices should be considered when choosing a primary key, there is a little more freedom to break the rules on occasion.
In addition, CockroachDB uses the primary key to distribute the records in a cluster. This means we need to add one additional consideration when designing our key:
- Should distribute well in a cluster.
There are two types of keys we can consider when making our decision.
- A “natural key” uses the data that is already present in the record.
- A “surrogate key” allows the database to generate a new key and assign it to the record.
Within the SQL community, there is significant debate over whether to use natural or surrogate keys. We won’t try to resolve that debate, but we’ll present the options with some general recommendations.
When to use Natural Keys
Consider the address of a house or building. It is made up of multiple components (building number, street name, etc.) that, when taken together, uniquely identify the property. The address is part of the property’s data and therefore represents a natural key.
As an example:
This address will uniquely identify a single location in New York City (Cockroach Labs). It can not be mistaken for any other location. If you want to share the location, you can provide that address and it can be reliably used to locate the property.
One of the key advantages of using a natural key is that it does not require any additional information than what is already in the record. This means it takes less storage space. However, in a scalable database like CockroachDB this is less important than it might be in other databases.
In addition, a natural key is often used when querying the database. For example, if we wanted to find all of the properties on West 25th Street in New York, our search could use a portion of the primary key. This means that we may not need to add an additional index and our query will be relatively efficient (assuming we set up the key properly).
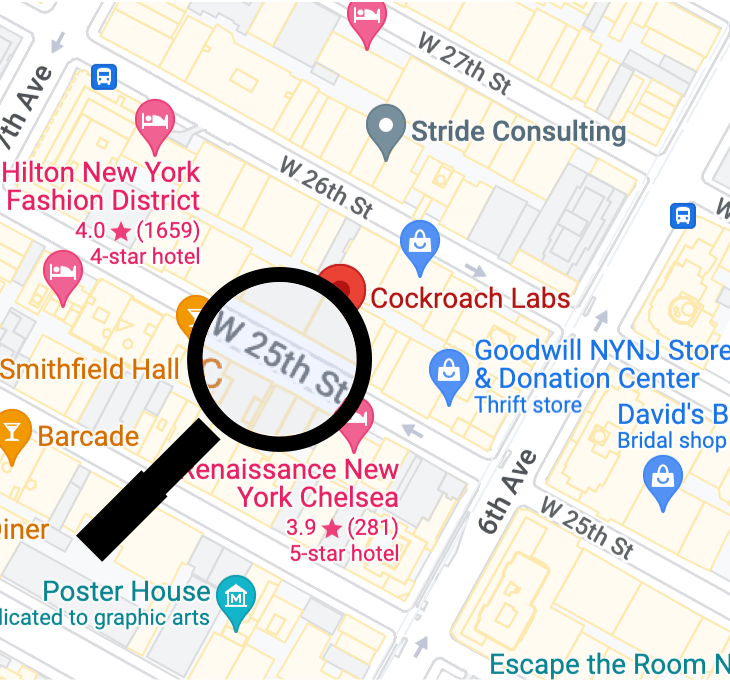
Querying an Address
However, there are cases where a natural key might not be a good fit. If that key is shared in some way, especially outside of the database, there may be security concerns with the key. Sometimes, the key is too long or complex and we would prefer something simpler. Some records simply don’t have a natural way of identifying them.
Regardless of the reason, when we find ourselves without a suitable natural key, we need to reach for an alternative.
When to use Surrogate Keys
What if we wanted to identify a person? On the surface, this seems easy. You identify a person using their first and last name. However, many people share the same name. This makes it an unsuitable primary key because it can’t guarantee uniqueness.
Instead, we might look at other information related to a person. For example:
- Phone Number
- Address
- Email Address
- Etc…
The phone number and address might be shared by multiple people living in the same place. So they don’t provide the required uniqueness.
The email address is promising because most people have their own email address, so it might be unique. Unfortunately, it also has some loopholes. Some people may not have an email address at all. Others people may share their email address with family members. Or it may be a business email with many people using it.
All of this means that an email address might be insufficient. However, sometimes we can make it work by applying special business rules. For example, requiring all users to have a unique email address. This may disqualify some users, but from a business perspective, maybe that’s okay.
But let’s assume we’ve decided that an email address is not going to work? What’s next?
The next option is to use a surrogate key. A surrogate key is a unique identifier synthesized by the database or application. It is not originally part of the data itself.
Governments figured this out many years ago and began assigning unique identifiers to individuals (eg. Social Security Numbers in the USA, Social Insurance Numbers in Canada, National Insurance Numbers in the UK, etc). This is a synthetic identifier that has been assigned to uniquely identify the person. These synthetic identifiers have become so ubiquitous that they are now considered natural keys, even though they started out as surrogates. However, because they have become so ubiquitous, we need to be careful. Exposing them could create security risks.

Instead, we often prefer to let the database generate a new surrogate Id for us. A commonly recommended pattern in legacy SQL databases is to use an automatically incrementing number as the primary key. However, this has its own security risks because those Ids are “guessable”. And, in a distributed database such as CockroachDB, this has other consequences we need to take into account.
The challenge of distributing records
Remember, CockroachDB uses the primary key for more than just identifying or querying a record. It is also used to determine how records are distributed in the cluster.
Without going into detail, the important thing to understand is that CockroachDB will sort and then divide the primary keys into ranges. These ranges will be distributed across the cluster (for more information see the free course: Introduction to CockroachDB & Distributed SQL.
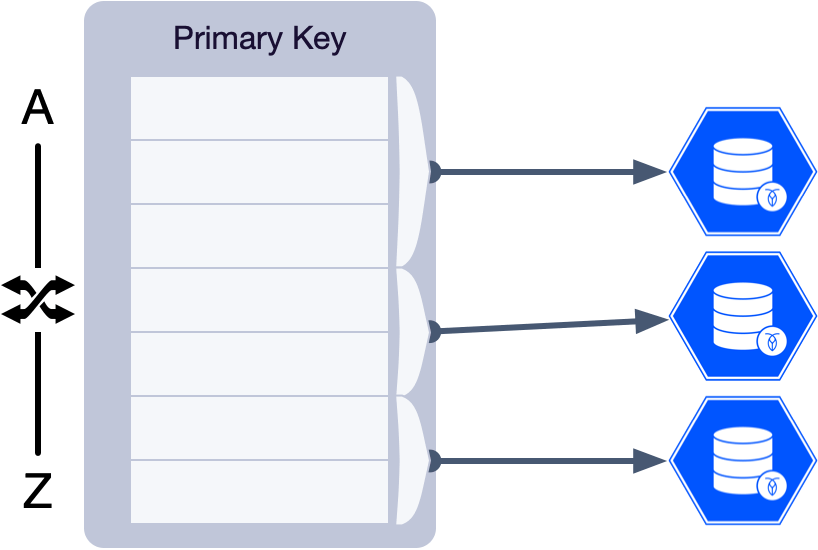
The problem with an automatically incrementing Id is that when you sort and divide the keys, all the newer entries end up in the last range. This creates a hotspot in your cluster because all of the new inserts will target that single range. In addition, in many applications, newer records are accessed more frequently than older ones (eg. social media feeds), so the read traffic may suffer from hotspots as well.
The problem of distribution can apply even in natural keys. For example, an address seems like a good natural key in a lot of cases. However, some applications experience heavier traffic in certain regions at certain times of the day. In a food delivery application, the traffic in New York during the lunch hour might create a significant amount of load. If we rely on the address to distribute across our cluster, it creates a potential hotspot because the New York records may end up in the same range. Hopefully, in this case, other major eastern cities will balance out the load. But if it doesn’t we may want to consider a surrogate key instead.
So, when we find ourselves in a situation where we need to use a surrogate key, what should we use instead of an auto-incrementing number?
Universally Unique Identifiers (UUIDs)
The recommended approach for generating surrogate keys in CockroachDB is to use a Universally Unique Identifier (UUID). These are sometimes also known as Globally Unique Identifiers (GUID).
There are several advantages to using a UUID as the primary key.
UUIDs, if generated with sufficient randomness, are functionally unique. CockroachDB implements a suitable UUID generator in the form of the SQL function gen_random_uuid(). You can use this function to generate unique UUIDs to be assigned to your primary key. A common pattern is to set it to the default value of your UUID column.
Generating UUIDs requires no central authority. This is different from an auto-incrementing number where you need a central authority to determine what the next number should be. With a UUID, they can be generated wherever needed and still be unique. Every CockroachDB node is capable of generating those Ids, which eliminates any central bottleneck.
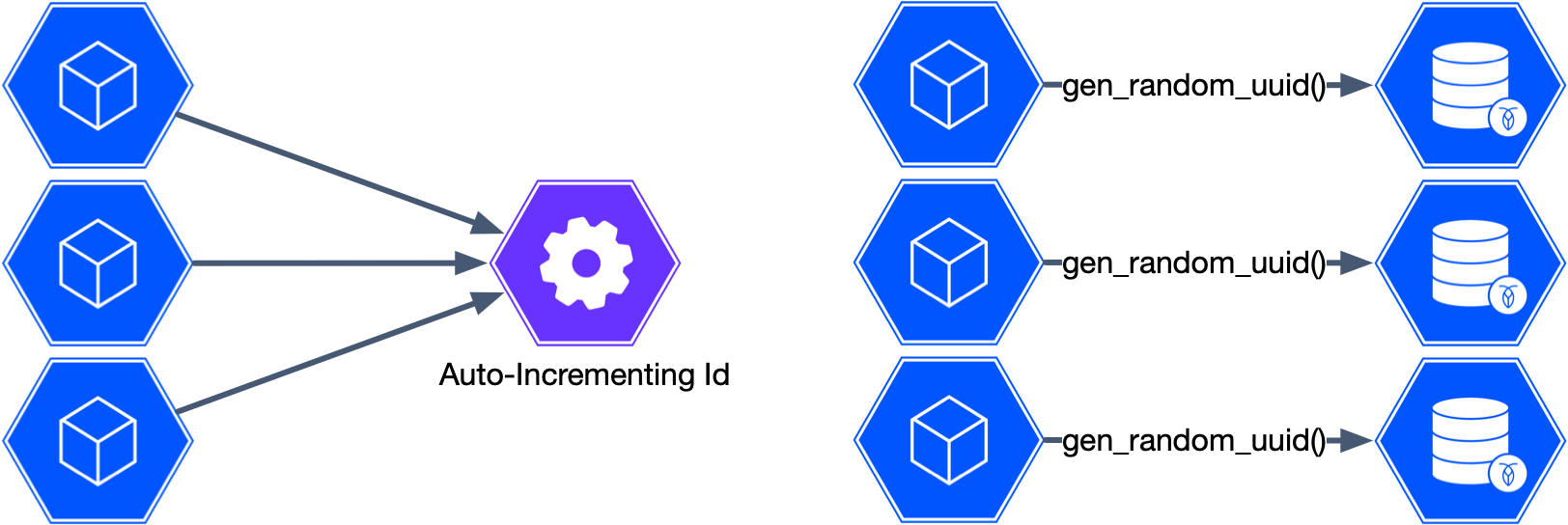
They also make an excellent key for distributing data in your CockroachDB cluster. Because of their random nature, each new UUID is likely to end up in a different range from the previous one. Your data will not be distributed by time, location, or any other logical grouping. As a result, reads and writes using the primary key will tend to be evenly distributed across the cluster, avoiding potential hotspots.
For these reasons, among others, it is recommended to use UUIDs whenever you need a surrogate key in CockroachDB.
Conclusion
Selecting a good primary key for your table is important to ensure that your database behaves in a healthy manner. Unfortunately, some of the standard approaches to selecting primary keys are outdated in a distributed database such as CockroachDB. Some people prefer natural keys when they are available, but you need to make sure they will distribute well, and they won’t create hotspots. If you decide to use a surrogate key for your table, use a UUID to ensure your data will be evenly distributed across the cluster.
If you want to learn more I recommend starting on our SQL Skills for Application Developers learning path. I know there are a lot of online learning resources for SQL, but most of them are made for data scientists and DBAs. Whereas our SQL courses are intentionally built for application developers.